two-way anova - violação das pressuposições

Colegas, Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste. Por favor, tire um tempo para ver os resultados e depois peço uma ajuda. Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06 #Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16 A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações? Obrigado! -- Marcelo

Prezado, Marcelo Faça uma análise gráfica da dispersão dos resíduos, via função lm. Alguns testes de normalidade podem sugerir não normalidade. Porém, em alguns casos, somente alguns dados desviaram da "reta da normal". Exemplo: Analise <- lm (area ~ genotipo, data = cerato.dsc) Plot (Analise) Após o plot clique em algum botao, dentro da interfase do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade. Inclusive, o teste de Bartlett é bastante sensível a pressuposição de normalidade. Espero ter podido ajudar. Em sáb, 2 de mar de 2019 13:17, Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br escreveu:
Colegas,
Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste.
Por favor, tire um tempo para ver os resultados e depois peço uma ajuda.
Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06
#Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16
A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações?
Obrigado!
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
Prezado, Marcelo Faça uma análise gráfica da dispersão dos resíduos, via função lm. Alguns testes de normalidade podem sugerir não normalidade. Porém, em alguns casos, somente alguns dados desviaram da "reta da normal". Exemplo: Analise <- lm (area ~ genotipo, data = cerato.dsc) Plot (Analise) Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade. Inclusive, o teste de Bartlett é bastante sensível a pressuposição de normalidade. Espero ter podido ajudar. Em sáb, 2 de mar de 2019 13:17, Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br escreveu:
Colegas,
Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste.
Por favor, tire um tempo para ver os resultados e depois peço uma ajuda.
Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06
#Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16
A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações?
Obrigado!
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
On 02/03/19 at 01:57, Gilson Geraldo Soares de Oliveira Júnior wrote:
Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade.
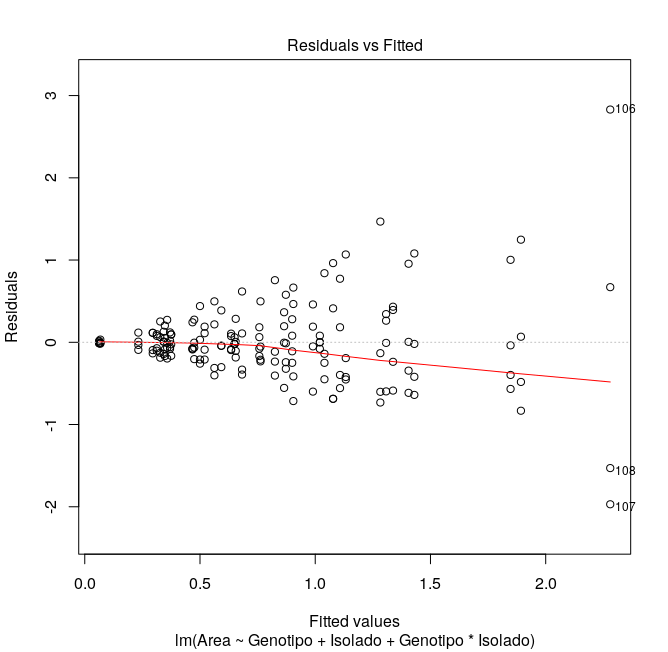
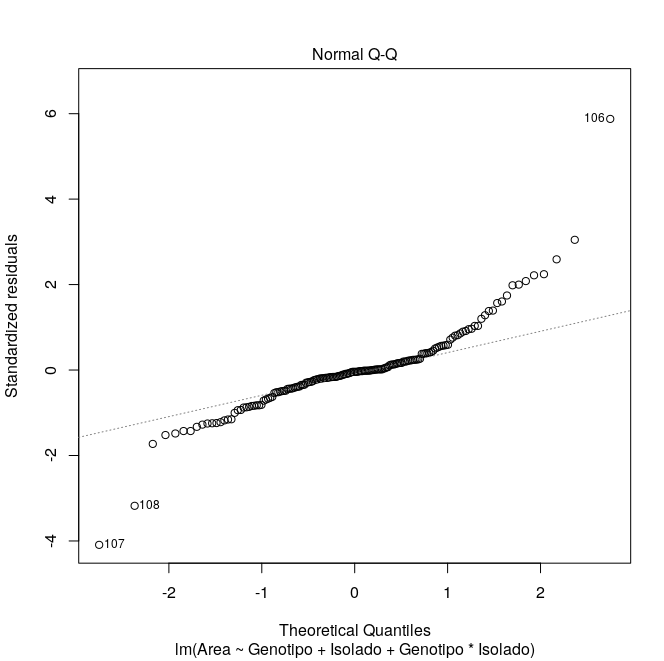
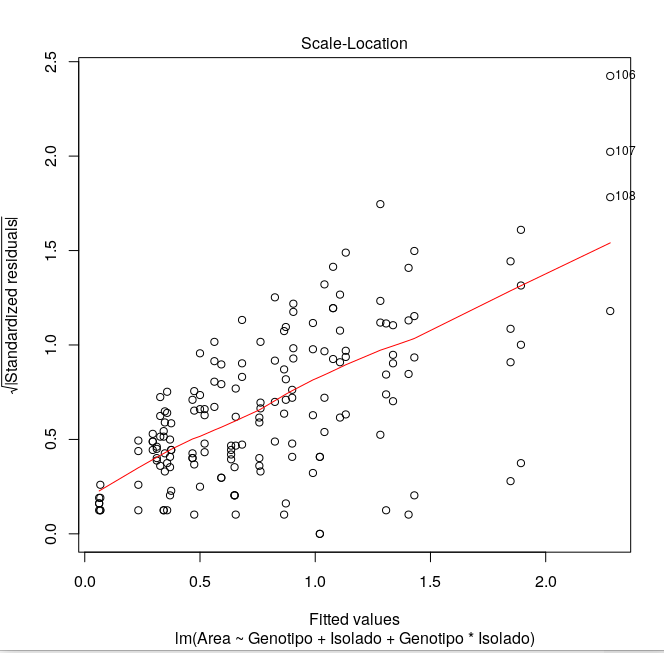
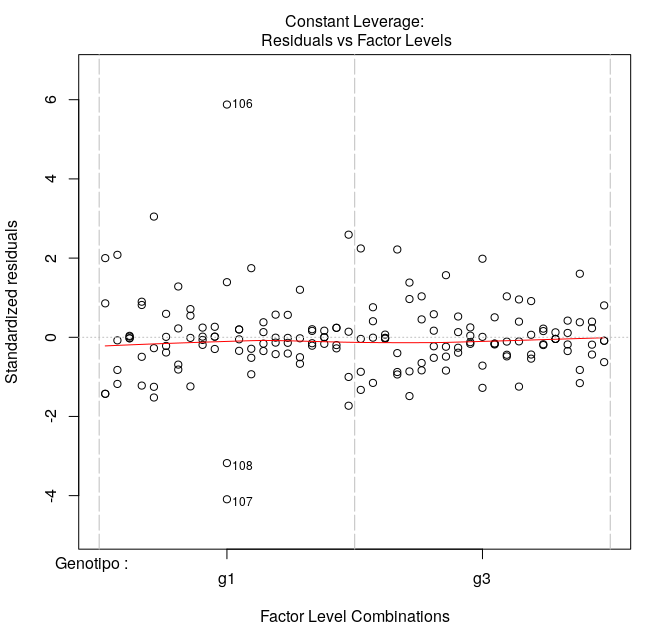
Gilson, Eu fiz essa verificação (gráficos em anexo). Há três observações que estão "fora". Eu utilizei o pacote bestNormalize e ele informa que a melhora transformação seria Log_b(x+a)[1]. Mas, eu não queria transformar os dados só por esses três outliers. 1. https://rdrr.io/cran/bestNormalize/man/log_x.html Uma vez que se trata de uma tese, preciso de argumentos para justificar a não transformação. Por outro lado, se, de fato, os dados necessitarem de transformação, terei que fazer. E neste caso, o output do bestNormalize informa que o melhor é lob_b(x+a) e o segundo melhor é Yeo-Johnson[2]. 2. https://rdrr.io/cran/bestNormalize/man/yeojohnson.html Qualquer sugestão será muito bem vinda! Obrigado! -- Marcelo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Marcelo, Neste caso, verificando a análise gráfica, não acho que a normalidade foi um problema. Consideraria o gráfico robusto o suficiente para assumir que a maioria dos dados tiveram tendência de normalidade. Portanto, justificaria a não transformação. No entanto, a homocedasticidade foi um problema. Talvez este seja o pressuposto mais importante nesta análise. Analisando os testes de Bartlett e Levene, além da análise gráfica, diria que seus dados não foram homocedasticos. Sendo assim, a estatística paramétrica não seria a melhor forma de avaliação. Em sáb, 2 de mar de 2019 14:26, Marcelo Laia <marcelolaia@gmail.com escreveu:
On 02/03/19 at 01:57, Gilson Geraldo Soares de Oliveira Júnior wrote:
Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade.
Gilson,
Eu fiz essa verificação (gráficos em anexo).
Há três observações que estão "fora".
Eu utilizei o pacote bestNormalize e ele informa que a melhora transformação seria Log_b(x+a)[1]. Mas, eu não queria transformar os dados só por esses três outliers.
1. https://rdrr.io/cran/bestNormalize/man/log_x.html
Uma vez que se trata de uma tese, preciso de argumentos para justificar a não transformação.
Por outro lado, se, de fato, os dados necessitarem de transformação, terei que fazer. E neste caso, o output do bestNormalize informa que o melhor é lob_b(x+a) e o segundo melhor é Yeo-Johnson[2].
2. https://rdrr.io/cran/bestNormalize/man/yeojohnson.html
Qualquer sugestão será muito bem vinda!
Obrigado!
-- Marcelo

Seguindo a proposta do gilson, apos rodar o modelo utilizando aov ou lm veja a distribuição dos residuos graficamente através da função qqp do pacote CAR qqp(rstandard(modelo.lm),"norm") A função mostra um gráfico quantile-quantile da distribuição normal com uma banda de confiança 95% o que dá mais segurança na hora de tomar a decisão. On Mar 2 2019, at 2:39 pm, Gilson Geraldo Soares de Oliveira Júnior por (R-br) <r-br@listas.c3sl.ufpr.br> wrote:
Marcelo,
Neste caso, verificando a análise gráfica, não acho que a normalidade foi um problema. Consideraria o gráfico robusto o suficiente para assumir que a maioria dos dados tiveram tendência de normalidade. Portanto, justificaria a não transformação.
No entanto, a homocedasticidade foi um problema. Talvez este seja o pressuposto mais importante nesta análise. Analisando os testes de Bartlett e Levene, além da análise gráfica, diria que seus dados não foram homocedasticos. Sendo assim, a estatística paramétrica não seria a melhor forma de avaliação.
Em sáb, 2 de mar de 2019 14:26, Marcelo Laia <marcelolaia@gmail.com (mailto:marcelolaia@gmail.com) escreveu:
On 02/03/19 at 01:57, Gilson Geraldo Soares de Oliveira Júnior wrote:
Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade.
Gilson, Eu fiz essa verificação (gráficos em anexo). Há três observações que estão "fora". Eu utilizei o pacote bestNormalize e ele informa que a melhora transformação seria Log_b(x+a)[1]. Mas, eu não queria transformar os dados só por esses três outliers.
1. https://rdrr.io/cran/bestNormalize/man/log_x.html Uma vez que se trata de uma tese, preciso de argumentos para justificar a não transformação.
Por outro lado, se, de fato, os dados necessitarem de transformação, terei que fazer. E neste caso, o output do bestNormalize informa que o melhor é lob_b(x+a) e o segundo melhor é Yeo-Johnson[2].
2. https://rdrr.io/cran/bestNormalize/man/yeojohnson.html Qualquer sugestão será muito bem vinda! Obrigado! -- Marcelo
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forne�a c�digo m�nimo reproduz�vel.
On 02/03/19 at 03:51, Fernando Souza wrote:
Seguindo a proposta do gilson, apos rodar o modelo utilizando aov ou lm veja a distribuição dos residuos graficamente através da função qqp do pacote CAR qqp(rstandard(modelo.lm),"norm")
Olá Fernando, Eu não conhecia essa função do pacote car. Bem massa, pois ela mostra as linhas de confiança. Com base no pacote bestNormalize, eu transformei os dados e observei os gráficos. Inclusive, com a função qqp todos ficam dentro dos 95%. Ou seja, a questão da normalidade foi resolvida. Mas, a homogeneidade ainda ficou esquisita quando incluo a interação: Com a interação: Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 2.2615 0.0002938 *** 126 Sem interação: só Genotipo Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 3.1509 0.07772 . 166 Sem interação: só Isolado Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 20 1.5658 0.06859 . 147 Em anexo os gráficos após transformação. Agradeço, imensamente, pela inestimável ajuda de ambos! -- Marcelo
{kind=link}
tente rodar usando a abordagem generalisada implementada na função gls do pacote nlme. nela é possivel afrouxar o pressuposto de homocedasticidade exigido pela função lm,aov, através do argumento weights der uma olhada no manual Em sáb, 2 de mar de 2019 5:56 PM, Marcelo Laia <marcelolaia@gmail.com escreveu:
On 02/03/19 at 03:51, Fernando Souza wrote:
Seguindo a proposta do gilson, apos rodar o modelo utilizando aov ou lm veja a distribuição dos residuos graficamente através da função qqp do pacote CAR qqp(rstandard(modelo.lm),"norm")
Olá Fernando,
Eu não conhecia essa função do pacote car. Bem massa, pois ela mostra as linhas de confiança.
Com base no pacote bestNormalize, eu transformei os dados e observei os gráficos. Inclusive, com a função qqp todos ficam dentro dos 95%. Ou seja, a questão da normalidade foi resolvida. Mas, a homogeneidade ainda ficou esquisita quando incluo a interação:
Com a interação: Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 2.2615 0.0002938 *** 126
Sem interação: só Genotipo Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 3.1509 0.07772 . 166
Sem interação: só Isolado Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 20 1.5658 0.06859 . 147
Em anexo os gráficos após transformação.
Agradeço, imensamente, pela inestimável ajuda de ambos!
-- Marcelo

Concordo com o Fernando Sousa, é a melhor opção. Normalidade pode até deixar de ser atendida, desde que não seja exagerada, mas homocedasticidade não. Alguns autores usam a gls para “fugir” desse problema. Em sáb, 2 de mar de 2019 às 18:19, Fernando Souza por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
tente rodar usando a abordagem generalisada implementada na função gls do pacote nlme. nela é possivel afrouxar o pressuposto de homocedasticidade exigido pela função lm,aov, através do argumento weights der uma olhada no manual
Em sáb, 2 de mar de 2019 5:56 PM, Marcelo Laia <marcelolaia@gmail.com escreveu:
On 02/03/19 at 03:51, Fernando Souza wrote:
Seguindo a proposta do gilson, apos rodar o modelo utilizando aov ou lm veja a distribuição dos residuos graficamente através da função qqp do pacote CAR qqp(rstandard(modelo.lm),"norm")
Olá Fernando,
Eu não conhecia essa função do pacote car. Bem massa, pois ela mostra as linhas de confiança.
Com base no pacote bestNormalize, eu transformei os dados e observei os gráficos. Inclusive, com a função qqp todos ficam dentro dos 95%. Ou seja, a questão da normalidade foi resolvida. Mas, a homogeneidade ainda ficou esquisita quando incluo a interação:
Com a interação: Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 2.2615 0.0002938 *** 126
Sem interação: só Genotipo Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 3.1509 0.07772 . 166
Sem interação: só Isolado Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 20 1.5658 0.06859 . 147
Em anexo os gráficos após transformação.
Agradeço, imensamente, pela inestimável ajuda de ambos!
-- Marcelo
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- Diego dos Santos Vieira Engenheiro Florestal
Concordo com as opções apresentadas. Alem disso, é natural que sem interação a homocedasticidade possa apresentar resultados diferentes daquelas expostas quando rodou os dados com a interação. A estatística não parametrica, nestes casos, é a melhor opção, dado os problemas de homocedasticidade. Como dito pelo Diego, a normalidade é o mais "tranquilo" dentro os pressupostos. Em sáb, 2 de mar de 2019 18:29, Diego Vieira por (R-br) < r-br@listas.c3sl.ufpr.br escreveu:
Concordo com o Fernando Sousa, é a melhor opção. Normalidade pode até deixar de ser atendida, desde que não seja exagerada, mas homocedasticidade não. Alguns autores usam a gls para “fugir” desse problema.
Em sáb, 2 de mar de 2019 às 18:19, Fernando Souza por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
tente rodar usando a abordagem generalisada implementada na função gls do pacote nlme. nela é possivel afrouxar o pressuposto de homocedasticidade exigido pela função lm,aov, através do argumento weights der uma olhada no manual
Em sáb, 2 de mar de 2019 5:56 PM, Marcelo Laia <marcelolaia@gmail.com escreveu:
On 02/03/19 at 03:51, Fernando Souza wrote:
Seguindo a proposta do gilson, apos rodar o modelo utilizando aov ou lm veja a distribuição dos residuos graficamente através da função qqp do pacote CAR qqp(rstandard(modelo.lm),"norm")
Olá Fernando,
Eu não conhecia essa função do pacote car. Bem massa, pois ela mostra as linhas de confiança.
Com base no pacote bestNormalize, eu transformei os dados e observei os gráficos. Inclusive, com a função qqp todos ficam dentro dos 95%. Ou seja, a questão da normalidade foi resolvida. Mas, a homogeneidade ainda ficou esquisita quando incluo a interação:
Com a interação: Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 2.2615 0.0002938 *** 126
Sem interação: só Genotipo Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 3.1509 0.07772 . 166
Sem interação: só Isolado Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 20 1.5658 0.06859 . 147
Em anexo os gráficos após transformação.
Agradeço, imensamente, pela inestimável ajuda de ambos!
-- Marcelo
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- Diego dos Santos Vieira Engenheiro Florestal _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
Observe que o gráfico de homocedasticidade possui uma tendência nítida de cone, característico de heterocedasticidade (os livros de estatística mostram essa tendência). O de normalidade me parece não apresentar normalidade, apenas os resíduos do meio estão concentrados, as pontas estão bastante descoladas. Eu optaria pela estatística não paramétrica ou glm. Abraço. Em sex, 22 de mar de 2019 às 18:44, Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
On 02/03/19 at 01:57, Gilson Geraldo Soares de Oliveira Júnior wrote:
Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade.
Gilson,
Eu fiz essa verificação (gráficos em anexo).
Há três observações que estão "fora".
Eu utilizei o pacote bestNormalize e ele informa que a melhora transformação seria Log_b(x+a)[1]. Mas, eu não queria transformar os dados só por esses três outliers.
1. https://rdrr.io/cran/bestNormalize/man/log_x.html
Uma vez que se trata de uma tese, preciso de argumentos para justificar a não transformação.
Por outro lado, se, de fato, os dados necessitarem de transformação, terei que fazer. E neste caso, o output do bestNormalize informa que o melhor é lob_b(x+a) e o segundo melhor é Yeo-Johnson[2].
2. https://rdrr.io/cran/bestNormalize/man/yeojohnson.html
Qualquer sugestão será muito bem vinda!
Obrigado!
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- Diego dos Santos Vieira Engenheiro Florestal
Eu transformaria. Usaria a transformação Box Cox que resolve a maioria dos casos em que tive trabalhando. Em sex, 22 de mar de 2019 às 22:37, Diego Vieira <diegovieir4@gmail.com> escreveu:
Observe que o gráfico de homocedasticidade possui uma tendência nítida de cone, característico de heterocedasticidade (os livros de estatística mostram essa tendência). O de normalidade me parece não apresentar normalidade, apenas os resíduos do meio estão concentrados, as pontas estão bastante descoladas. Eu optaria pela estatística não paramétrica ou glm. Abraço.
Em sex, 22 de mar de 2019 às 18:44, Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br> escreveu:
On 02/03/19 at 01:57, Gilson Geraldo Soares de Oliveira Júnior wrote:
Após o plot clique em algum botao, dentro da interface do R, para surgirem 4 gráficos. Os dois primeiros são homocedasticidade e normalidade. Faça a análise gráfica e verifique a dispersao dos pontos entorno da "reta" de normalidade.
Gilson,
Eu fiz essa verificação (gráficos em anexo).
Há três observações que estão "fora".
Eu utilizei o pacote bestNormalize e ele informa que a melhora transformação seria Log_b(x+a)[1]. Mas, eu não queria transformar os dados só por esses três outliers.
1. https://rdrr.io/cran/bestNormalize/man/log_x.html
Uma vez que se trata de uma tese, preciso de argumentos para justificar a não transformação.
Por outro lado, se, de fato, os dados necessitarem de transformação, terei que fazer. E neste caso, o output do bestNormalize informa que o melhor é lob_b(x+a) e o segundo melhor é Yeo-Johnson[2].
2. https://rdrr.io/cran/bestNormalize/man/yeojohnson.html
Qualquer sugestão será muito bem vinda!
Obrigado!
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- Diego dos Santos Vieira Engenheiro Florestal
-- Diego dos Santos Vieira Engenheiro Florestal

Prezado Marcelo, Segue artigo que pode lhe ser útil quanto à suposição de normalidade. Abraço, Rodrigo On Sat, Mar 2, 2019 at 1:17 PM Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Colegas,
Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste.
Por favor, tire um tempo para ver os resultados e depois peço uma ajuda.
Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06
#Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16
A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações?
Obrigado!
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
-- Rodrigo Campos
Na minha busca por informação (para o meu conhecimento, mesmo) a respeito do tema, recebi a inestimável ajuda de vocês e também encontrei algumas coisas na internet. Daquilo que encontrei na net, eis um artigo que achei interessante: https://www.r-bloggers.com/normality-tests-don%E2%80%99t-do-what-you-think-t... ou https://wp.me/pMm6L-fpD Abraços a todos. Laia ML
Colegas,
Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste.
Por favor, tire um tempo para ver os resultados e depois peço uma ajuda.
Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06
#Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16
A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações?
Obrigado!
-- Marcelo
-- Marcelo

Embora chegando atrasado a esta discussão, gostaria de contribuir com algumas informações. Primeiramente, uma questão de conceito: há uma certa confusão na literatura, especialmente quando ela é ligada a algum manual de SW recente a respeito da "premissa de normalidade" numa ANOVA. Não é distribuição dos *dados* que precisa ser Gaussiana, mas sim a distribuição dos resíduos após a ANOVA (que na verdade é um elegante teste numa regressão linear onde a hipótese é que certos "fatores" mudam a média da regressão. Esse *equívoco* ele é perpetrado e perpetuado por "helps' e manuais de SW que seus fabricantes para ganhar na guerra das *features* findam por transformá-los em "boas práticas" ou exame obrigatório (quando os indicam para os *dados*). Um "contra exemplo" poderia ser ilustrativo. Um experimentador resolve testar uma resposta a um certo estímulo com três tratamentos, e por conveniência, custo ou mesmo necessidade, a variável independente precisa ser uma medida cuja distribuição é o conjunto de {1,2,3,...,10} unidades de medida, e a resposta o conjunto de dez respostas, para três fatores A, B, C. Ora, como a ANOVA não passa de um uma regressão linear já com resultados formatados para responder a questão a respeito dos tratamentos, *por premissa*, os vetores de respostas serão números proporcionais ao vetor da VI e tampouco nenhum dos três teria distribuição gaussiana (a soma pode até se aproximar, embora para trinta casos ainda esteja na "beirada", [CLT, G-K, etc.]). Mas como a matemática é exata e os instrumentos de medida não, nosso antepassado notou que tanto as medidas da VI como a resposta "flutuam" em volta de um valor real, que se for somado subtraído (se fosse conhecido 😎) geraria uns desvios cuja probalidade de serem grandes diminui quanto maior o são e a relação funcional dessa probabilidade tem o formato do sino (a curva que hoje o homenageamos dando-lhe o nome de Curva de Gauss). Portanto no nosso costume de análise a gente "faz de conta" que as medidas da VI estão "certas" e que o desvio é uma distribuição de Gauss com média zero e desvio padrão que é consequência do desvio padrão da medida vezes o coeficiente angular da relação funcional (premissa de ser linear na ANOVA) somado ao desvio padrão das medidas das respostas. ESSA distribuição de valores os *resíduos* que precisam ser normais (gaussianos). Para isto não virar um tratado, estou eludindo discussões sobre a distribuição mais conveniente dos dados das variáveis e outros aspectos que entram em 'desenho' (projeto pois é trad. da palavra inglesa *design*) de experimentos, etc. Além disso, para não colocar ene referências bibliográficas, coloco aqui o saber de mestres como Thomas Lumley (consultor da OMS) e seus coautores THE IMPORTANCE OF THE NORMALITY ASSUMPTION IN LARGE PUBLIC HEALTH DATA SETS <https://www.annualreviews.org/doi/pdf/10.1146/annurev.publhealth.23.100901.140546> . Para os que não tenham tempo de ver o documento, submeto a vocês um resumo dos pontos importantes: 1. É bastante disseminada a crença que o teste *t* e a regressão linear são válidos apenas para resultados (desfechos) de distribuição normal. 2. Essa ideia está errada. 3. Esses testes (e acrescento eu por tabela ANOVA) são adequados para determinar se as diferenças têm significação estatística. 4. O xis da questão não está nas distribuições, mas sim a detecção e estimação das diferenças nas médias dos desfechos responde à questão científica subjacente. HTH -- Cesar Rabak On Thu, Mar 28, 2019 at 12:18 PM Marcelo Laia por (R-br) < r-br@listas.c3sl.ufpr.br> wrote:
Na minha busca por informação (para o meu conhecimento, mesmo) a respeito do tema, recebi a inestimável ajuda de vocês e também encontrei algumas coisas na internet.
Daquilo que encontrei na net, eis um artigo que achei interessante:
https://www.r-bloggers.com/normality-tests-don%E2%80%99t-do-what-you-think-t...
ou
Abraços a todos.
Laia ML
Colegas,
Estamos com um conjunto de dados que viola pressuposições da ANOVA, principalmente a normalidade. Eu já li, por diversas vezes, que essa violação pode não ser tão danosa assim, devido a robustez do teste.
Por favor, tire um tempo para ver os resultados e depois peço uma ajuda.
Genotipo e Isolado são fatores Area está em centímetros quadrados
leveneTest(Area ~ Genotipo*Isolado, data = cerato.desc) Levene's Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 41 3.4755 4.718e-08 *** 126
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
cat("Normality p-values by Factor Genotipo: ") for (i in unique(factor(cerato.desc$Genotipo))){ cat(shapiro.test(cerato.desc[cerato.desc$Genotipo==i, ]$Area)$p.value," ") } 7.074459e-10 3.200422e-06
#Shapiro-Wilk normality tests by Isolado for (i in unique(factor(cerato.desc$Isolado))){ cat(shapiro.test(cerato.desc[cerato.desc$Isolado==i, ]$Area)$p.value," ") } 0.09534117 0.4006495 0.6065291 0.2093362 0.6138097 0.5604402 0.1302976 0.3135567 0.905537 0.7294285 0.0966383 0.1512716 0.8469947 0.1226855 0.2713435 0.9695489 0.2747097 0.5476302 0.0008750702 0.03693436 0.4197769
bartlett.test(Area~Genotipo,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Genotipo Bartlett's K-squared = 19.769, df = 1, p-value = 8.738e-06
bartlett.test(Area~Isolado,data = cerato.desc )
Bartlett test of homogeneity of variances
data: Area by Isolado Bartlett's K-squared = 171.26, df = 20, p-value < 2.2e-16
A pergunta é: mesmo com esses resultados eu poderia afirmar que o teste, neste caso, será robusto o suficiente para essas violações?
Obrigado!
-- Marcelo
-- Marcelo _______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e fornea cdigo mnimo reproduzvel.
participantes (6)
-
 Cesar Rabak
Cesar Rabak -
 Diego Vieira
Diego Vieira -
 Fernando Souza
Fernando Souza -
 Gilson Geraldo Soares de Oliveira Júnior
Gilson Geraldo Soares de Oliveira Júnior -
 Marcelo Laia
Marcelo Laia -
 Rodrigo Campos
Rodrigo Campos