
19 Abr
2017
19 Abr
'17
00:34
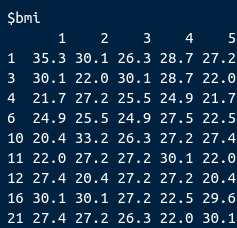
Usando o pacote mice fiz o seguinte teste (imputação de dados): imp <- mice(nhanes) Isso gerou 5 conjuntos de dados imputados: imp$imp$bmi Eu gostaria de entender como escolher o melhor dataset imputado Por exemplo, para bmi (acima) qual das 5 colunas será a melhor escolha? Eu achei vários exemplos usando regressão logistica, mas eu não vou rodar uma regressão logistica, vou usar os dados para criar uma rede bayesiana. Alguém poderia me ajudar por favor? -- *In Jesu et Maria* *Obrigado* *Prof. Elias Carvalho* *"Felix, qui potuit rerum cognoscere causas" (Virgil 29 BC)"Blessed is he who has been able to understand the cause of things"*
{kind=link}