Distribuição para regressão de resposta binária

Prezados, De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados. Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência. Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese... O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito. [image: Imagem inline 1] A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo? Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,). Seguem alguns resultados, caso possa ajudar em algo. Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever. Há braços, Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for quasipoisson family taken to be 0.6036898) Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA Number of Fisher Scoring iterations: 5 -- MARCOS BISSOLI Faculdade de Nutrição Universidade Federal de Alfenas Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli Alfenas, Minas Gerais, Brasil *****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE Eu apoio a ENEN "na luta por um Brasil sem fome" "por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto) E nunca votarei no PSDB/DEM!
{kind=link}

Tem ruído aí nesta explicação. Na verdade, o que o "epidemiologista" alegou, não me convenceu. Em 7 de fev de 2017 9:14 PM, "Marcos Bissoli via R-br" < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
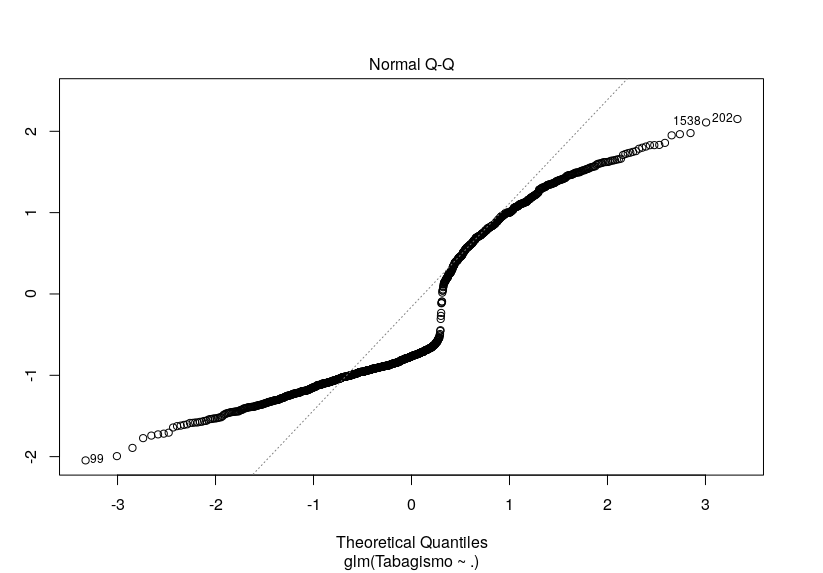
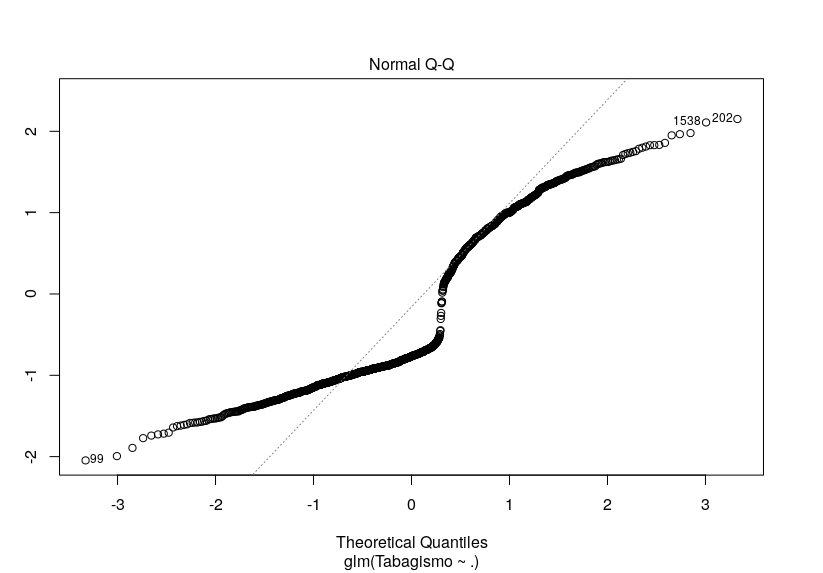
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Olá Leonard, Muito obrigado pelo interesse no debate. Minha afirmação baseada em epidemiologistas é, na verdade, baseada numa série de artigos que venho estudando recentemente. Seguem algumas referências, dentre outras várias, sobre as quais venho me fundamentando. ZOU, G. A Modified Poisson Regression Approach to Prospective Studies with Binary Data. *American Journal of Epidemiology*, v. 159, n. 7, p. 702–706, 1 abr. 2004. COUTINHO, L. M. S.; SCAZUFCA, M.; MENEZES, P. R. Métodos para estimar razão de prevalência em estudos de corte transversal. *Revista de Saúde Pública*, v. 42, n. 6, p. 992–998, dez. 2008. BARROS, A. J.; HIRAKATA, V. N. Alternatives for logistic regression in cross-sectional studies: an empirical comparison of models that directly estimate the prevalence ratio. *BMC Medical Research Methodology*, v. 3, n. 1, p. 21, 20 dez. 2003. FRANCISCO, P. M. S. B. et al. Medidas de associação em estudo transversal com delineamento complexo: razão de chances e razão de prevalência. *Revista Brasileira de Epidemiologia*, v. 11, n. 3, p. 347–355, set. 2008. WILLIAMSON, T.; ELIASZIW, M.; FICK, G. H. Log-binomial models: exploring failed convergence. *Emerging themes in epidemiology*, v. 10, n. 1, p. 14, 13 dez. 2013. Abraços fraternos, Marcos Em 7 de fevereiro de 2017 22:22, Leonard Assis via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Tem ruído aí nesta explicação. Na verdade, o que o "epidemiologista" alegou, não me convenceu.
Em 7 de fev de 2017 9:14 PM, "Marcos Bissoli via R-br" < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
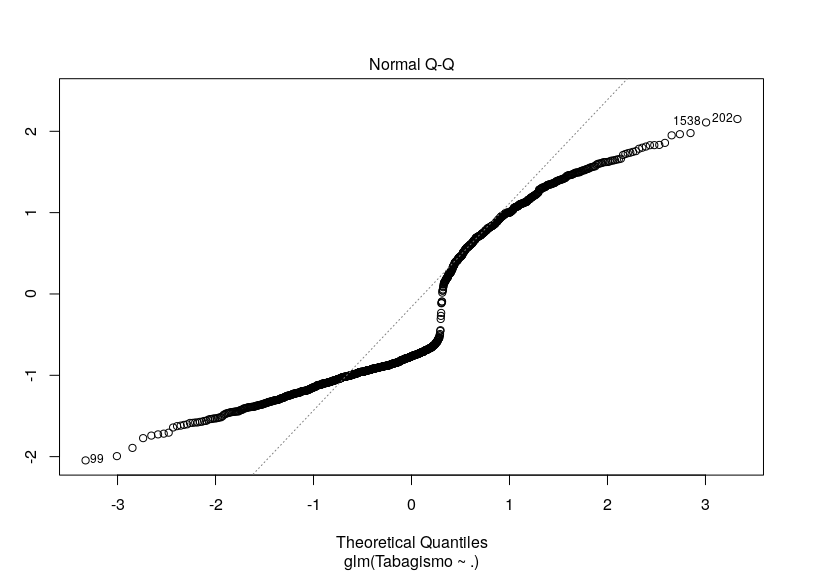
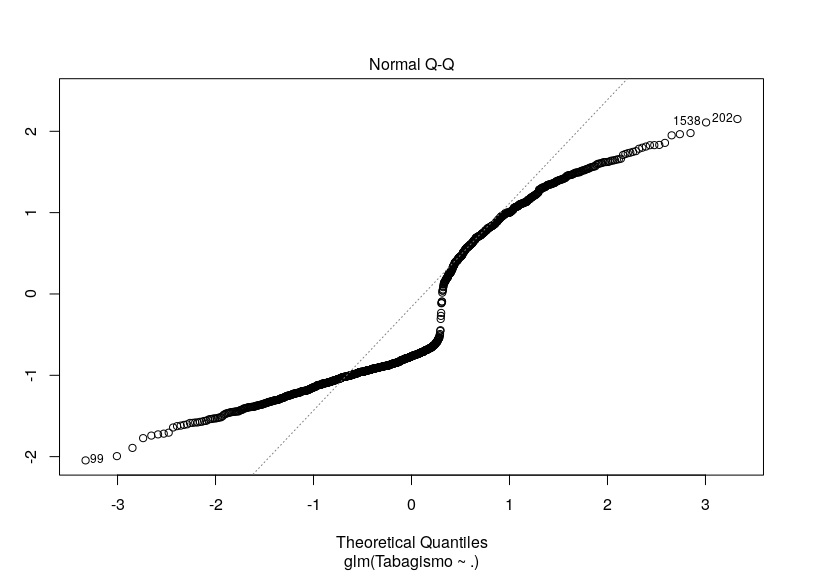
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI Faculdade de Nutrição Universidade Federal de Alfenas Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli Alfenas, Minas Gerais, Brasil *****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE Eu apoio a ENEN "na luta por um Brasil sem fome" "por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto) E nunca votarei no PSDB/DEM!
{kind=link}
Prezados, À guisa de uma síntese das referências que enviei anteriormente... O problema maior da regressão logística é que diversos autores têm demonstrado que ela inflaciona os resultados de probabilidades nas associações entre exposições e desfechos. Mas antes de concluir sobre isso, talvez alguma teoria da Epidemiologia seja necessária. Matematicamente, a função de ligação da regressão logística (logit) gera como coeficiente a razão de chances. Sob o ponto de vista teórico, essa razão de produtos cruzados tem sido criticada por diversos epidemiologistas por não representar absolutamente nada em um processo saúde-doença: ela não representa qualquer indicador referenciável epidemiologicamente. Indicadores epidemiológicos são, basicamente, de morbidade (medida de doença) e mortalidade. Os dois principais indicadores de morbidade são a prevalência (resultado de estudo transversal) e incidência (fruto de delineamento longitudinal). Existem as razões de prevalência e de incidência, que sob um ponto de vista teórico estaria mais compatível com os pressupostos da Epidemiologia. Estas razões também são chamadas de risco relativo. A função de ligação "log" fornece coeficientes de regressão que são essas razões. Por isso a recomendação atual de se utilizar regressão log-binomial ou Poisson em modelos epidemiológicos. Além desses pressupostos de ordem mais teórica, há evidências estatísticas que vêm sendo divulgadas nestes artigos e outros muitos. A razão de chances aumenta muito quando temos uma prevalência/incidência da doença >20%, em relação à razão de risco. Dessa forma, a razão de chances tem sido delatada como uma medida que superestima efeitos de um fator causal sobre a variável resposta em modelos. Espero que o "ruído" possa, agora, ser mais audível. :D Há braços, Marcos Em 7 de fevereiro de 2017 22:22, Leonard Assis via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Tem ruído aí nesta explicação. Na verdade, o que o "epidemiologista" alegou, não me convenceu.
Em 7 de fev de 2017 9:14 PM, "Marcos Bissoli via R-br" < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
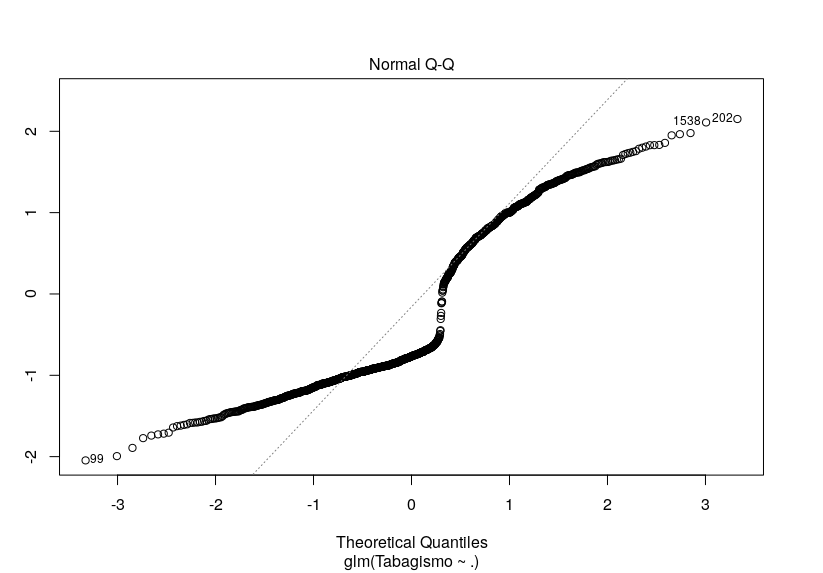
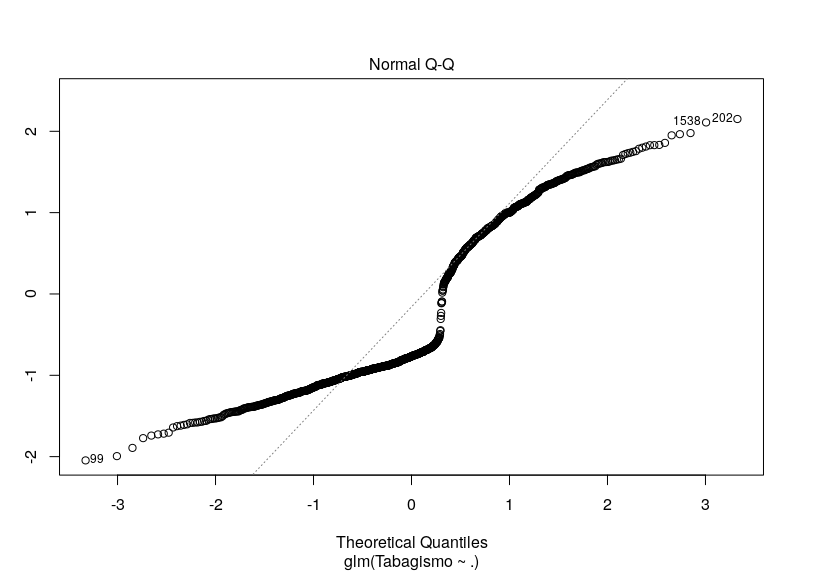
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI Faculdade de Nutrição Universidade Federal de Alfenas Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli Alfenas, Minas Gerais, Brasil *****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE Eu apoio a ENEN "na luta por um Brasil sem fome" "por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto) E nunca votarei no PSDB/DEM!
{kind=link}

Marcos, Você já pensou em utilizar modelo linear bi-segmentado? Se for uma bobagem muito grande, perdoe-me. Luiz Roberto Martins Pinto Prof. Pleno/DCET/UESC Laboratório de Estatística Computacional Universidade Estadual de Santa Cruz Ilhéus-Bahia-Brasil luizroberto.uesc@gmail.com skype: lrmpinto http://lattes.cnpq.br/2732314327604831 "*The s**cience exists because there are patterns. * * The patterns exist because God created them*. * The statistic exists to research the patterns that God created.*" Em 7 de fevereiro de 2017 20:14, Marcos Bissoli via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
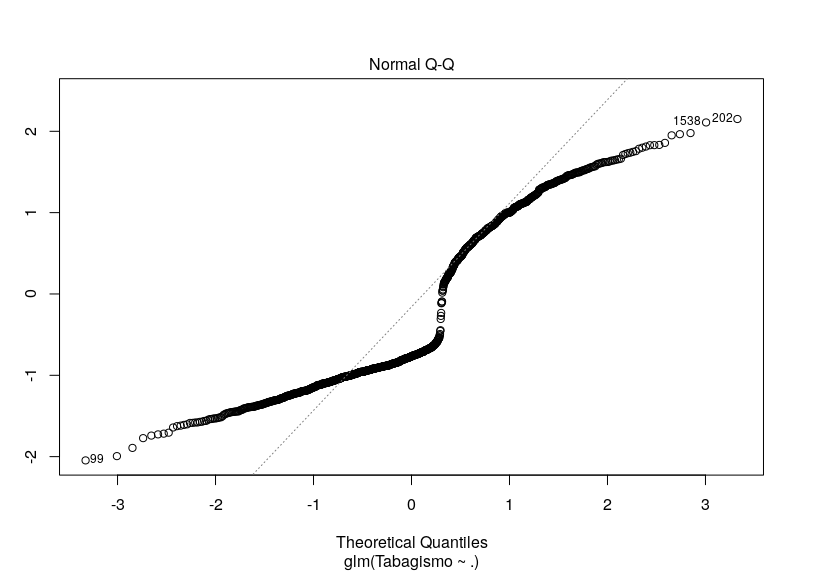
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Prezado Prof Luiz, Não conheço esta técnica. Certamente que não será nenhuma bobagem conhecê-la melhor. Alguma sugestão de literatura? Fiz alguma busca agora e não fui muito feliz em encontrar algo que teorize-a. Grato, Marcos Em 9 de fevereiro de 2017 11:27, Luiz Roberto Martins Pinto < luizroberto.uesc@gmail.com> escreveu:
Marcos,
Você já pensou em utilizar modelo linear bi-segmentado? Se for uma bobagem muito grande, perdoe-me.
Luiz Roberto Martins Pinto Prof. Pleno/DCET/UESC Laboratório de Estatística Computacional Universidade Estadual de Santa Cruz Ilhéus-Bahia-Brasil
luizroberto.uesc@gmail.com skype: lrmpinto http://lattes.cnpq.br/2732314327604831
"*The s**cience exists because there are patterns. * * The patterns exist because God created them*. * The statistic exists to research the patterns that God created.*"
Em 7 de fevereiro de 2017 20:14, Marcos Bissoli via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI Faculdade de Nutrição Universidade Federal de Alfenas Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli Alfenas, Minas Gerais, Brasil *****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE Eu apoio a ENEN "na luta por um Brasil sem fome" "por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto) E nunca votarei no PSDB/DEM!
{kind=link}

Marcos, Dei uma olhada "perfunctória" nas respostas e me fixei nos resultados de duas regressões que você enviou, na mensagem de nove do corrente 10h34, e a primeira mensagem dia sete. O que me salta os olhos nas duas regressões é o valor-p do intercepto: Na regressão do dia sete:
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 e nesta do dia nove:
ModeloLogistico <- glm(Tabagismo~.,data = TabModelagem,family = binomial(link = logit))> summary(ModeloLogistico) Call: glm(formula = Tabagismo ~ ., family = binomial(link = logit), data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -2.0034 -0.8824 -0.5459 1.0052 2.3721 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 1.215e+01 8.827e+02 0.014 0.989021 Note que em ambas com modelagem (funções de ligação levemente diferentes) diversa, mas com chamada sem nenhuma outra mudança em relação às variáveis explicativas x a dependente, o valor-p do intercepto não pode ser descartado como sendo zero. Isso faz sentido na sua análise? Outra questão que não achei fácil nas respostas, mas que é importante: quantos casos você tem para cada um desses fatores e variáveis (em outras palavras estão equilibrados esses fatores)? HTH -- Cesar Rabak 2017-02-09 15:03 GMT-02:00 Marcos Bissoli via R-br <r-br@listas.c3sl.ufpr.br
:
Prezado Prof Luiz,
Não conheço esta técnica. Certamente que não será nenhuma bobagem conhecê-la melhor. Alguma sugestão de literatura? Fiz alguma busca agora e não fui muito feliz em encontrar algo que teorize-a.
Grato,
Marcos
Em 9 de fevereiro de 2017 11:27, Luiz Roberto Martins Pinto < luizroberto.uesc@gmail.com> escreveu:
Marcos,
Você já pensou em utilizar modelo linear bi-segmentado? Se for uma bobagem muito grande, perdoe-me.
Luiz Roberto Martins Pinto Prof. Pleno/DCET/UESC Laboratório de Estatística Computacional Universidade Estadual de Santa Cruz Ilhéus-Bahia-Brasil
luizroberto.uesc@gmail.com skype: lrmpinto http://lattes.cnpq.br/2732314327604831
"*The s**cience exists because there are patterns. * * The patterns exist because God created them*. * The statistic exists to research the patterns that God created.*"
Em 7 de fevereiro de 2017 20:14, Marcos Bissoli via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
{kind=link}
Olá Cesar e amigos, Tive que apelar para o dicionário para conhecer a palavra "perfunctória". :D O problema do intercepto é corrigido quando eu ajusto a variância robusta. Veja:
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson(link = log))> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson(link = log), data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 (...)
RP.Poisson.Ceci(Mod1) Estimate Pr(>|z|) RP LCL UCL (Intercept) -1.245e+00 2.199e-04 0.288055 0.148852 0.557437
Mas o questionamento é bastante interessante. Em princípio, um intercepto sem significância poderia fazer sentido, sim, nos meus dados, no meu entender. Isso significaria que só existiriam tabagistas na presença dos efeitos em estudo? De fato, pouco provável, mas possível. Não, meus dados não são balanceados. Em verdade, isso NUNCA acontece em estudos observacionais. Eu não tenho controle algum, durante o delineamento, sobre as variáveis explicativas. Isso é a natureza de estudos epidemiológicos observacionais. Em alguns casos, como em delineamentos de coorte ou caso-controle, podemos ter algum controle de balanceamento, mas sempre apenas sobre uma única variável explicativa, e isso em geral é pouco comum, pois a ocorrência de censuras é inevitável. Isso também significaria uma circunstância especial, que mereceria algum procedimento amenizador? É importante frisar. O tabagismo é apenas uma de sete variáveis resposta que tenho em meu banco. Já modelei outras três e, não que tenha sido simples, mas cheguei a modelos com bom ajuste visual. Até agora, a única que "causou choque" pelo diagnóstico do qqPlot foi essa do Tabagismo. Acho que o Leonard afirmou que não dá muita importância a esses gráficos, e estou "precisando" me convencer disso e seguir em frente, pois os prazos começam a fazer mais efeito... Muito obrigado, mais uma vez. Saúde, paz e luz! Em 11 de fevereiro de 2017 01:27, Cesar Rabak <cesar.rabak@gmail.com> escreveu:
Marcos,
Dei uma olhada "perfunctória" nas respostas e me fixei nos resultados de duas regressões que você enviou, na mensagem de nove do corrente 10h34, e a primeira mensagem dia sete.
O que me salta os olhos nas duas regressões é o valor-p do intercepto:
Na regressão do dia sete:
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644
e nesta do dia nove:
ModeloLogistico <- glm(Tabagismo~.,data = TabModelagem,family = binomial(link = logit))> summary(ModeloLogistico) Call: glm(formula = Tabagismo ~ ., family = binomial(link = logit), data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -2.0034 -0.8824 -0.5459 1.0052 2.3721
Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 1.215e+01 8.827e+02 0.014 0.989021
Note que em ambas com modelagem (funções de ligação levemente diferentes) diversa, mas com chamada sem nenhuma outra mudança em relação às variáveis explicativas x a dependente, o valor-p do intercepto não pode ser descartado como sendo zero.
Isso faz sentido na sua análise?
Outra questão que não achei fácil nas respostas, mas que é importante: quantos casos você tem para cada um desses fatores e variáveis (em outras palavras estão equilibrados esses fatores)?
HTH -- Cesar Rabak
2017-02-09 15:03 GMT-02:00 Marcos Bissoli via R-br < r-br@listas.c3sl.ufpr.br>:
Prezado Prof Luiz,
Não conheço esta técnica. Certamente que não será nenhuma bobagem conhecê-la melhor. Alguma sugestão de literatura? Fiz alguma busca agora e não fui muito feliz em encontrar algo que teorize-a.
Grato,
Marcos
Em 9 de fevereiro de 2017 11:27, Luiz Roberto Martins Pinto < luizroberto.uesc@gmail.com> escreveu:
Marcos,
Você já pensou em utilizar modelo linear bi-segmentado? Se for uma bobagem muito grande, perdoe-me.
Luiz Roberto Martins Pinto Prof. Pleno/DCET/UESC Laboratório de Estatística Computacional Universidade Estadual de Santa Cruz Ilhéus-Bahia-Brasil
luizroberto.uesc@gmail.com skype: lrmpinto http://lattes.cnpq.br/2732314327604831
"*The s**cience exists because there are patterns. * * The patterns exist because God created them*. * The statistic exists to research the patterns that God created.*"
Em 7 de fevereiro de 2017 20:14, Marcos Bissoli via R-br < r-br@listas.c3sl.ufpr.br> escreveu:
Prezados,
De antemão peço desculpas se desvio o tópico da lista. Mas creio que o tema da mensagem é minimamente transversal aos aqui tratados.
Tenho uma variável resposta binária. Como a frequência da resposta é alta (38,11%), teóricos da Estatística aplicada à Epidemiologia sugerem que não seja usada uma regressão logística. Neste caso (de alta prevalência do desfecho), a primeira opção deveria ser uma log-binomial. Mas (e isso não é raro de ocorrer), minha log-binomial não apresentou convergência.
Quando não há convergência, os teóricos sugerem uma regressão de Poisson com variância robusta. Entretanto, como meus dados sugerem subdispersão, optei por um modelo de quasi-poisson. Isso já deu certo em outras análises que fiz para terceiros. Inclusive, tenho conseguido adaptar a variância robusta ao modelo de quasi-poisson. Mas justamente agora, com os dados de minha tese...
O diagnóstico visual está, ao meu ver, péssimo, para ajuste. A imagem anexa é do modelo de quasi-poisson. Mas experimentei todos os acima citados (logística e Poisson) e o gráfico não diferiu muito.
[image: Imagem inline 1]
A dúvida é... Há alguma outra alternativa de técnica de regressão que eu poderia tentar? Minhas variáveis explicativas são diversas, em quantidade e tipo (há contínuas, ordinais e binárias). Ou será (embora eu ache pouco provável) que este gráfico não significa um grande incômodo?
Fiz o teste de qui-quadrado da deviance residual e estranhamente o valor p está resultando em 1, tanto para Poisson quanto para quasi-Poisson. Um outro fato estranho é o pseudo R² de Nagelkerke ter acusado 20%: todas as outras minhas variáveis resposta não passaram de 12%. Não sei se é correto (consultei bibliografia que sugeria isso para a regressão logística), mas apliquei um teste de Hosmer e Lemeshow e ele acusou um bom ajuste do modelo, também (p = 0,2718). Até uma curva de ROC eu fiz e a área está grande no gráfico (mais uma técnica que não sei se deve ser aplicada além da regressão logística,).
Seguem alguns resultados, caso possa ajudar em algo.
Desde já agradeço qualquer comentário. E reforço minhas desculpas caso eu tenha desviado do tópico além do esperado, e desde já acato qualquer negativa em prosseguir o debate. Nesse caso, se possível, aceitaria sugestões de boas listas para debates nesse nível onde eu pudesse me inscrever.
Há braços,
Marcos Bissoli Faculdade de Nutrição Unifal-MG
Mod1 <- glm(Tabagismo~.,data = TabModelagem,family = quasipoisson)> summary(Mod1) Call: glm(formula = Tabagismo ~ ., family = quasipoisson, data = TabModelagem)
Deviance Residuals: Min 1Q Median 3Q Max -1.4867 -0.7821 -0.5889 0.5349 1.6624
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.245e+00 8.738e-01 -1.424 0.154644 factor.SexoDic.1 5.800e-01 8.273e-02 7.011 4.11e-12 *** factor.Branca.1 -8.332e-01 7.836e-01 -1.063 0.287863 factor.Negra.1 -8.210e-01 7.987e-01 -1.028 0.304185 factor.Parda.1 -9.009e-01 7.863e-01 -1.146 0.252163 factor.Amarela.1 -1.089e+00 8.481e-01 -1.284 0.199466 factor.SemReligiao.1 -9.670e-02 1.888e-01 -0.512 0.608566 factor.Catolica.1 -4.813e-01 1.862e-01 -2.585 0.009863 ** factor.Espirita.1 -1.235e-01 2.181e-01 -0.566 0.571230 factor.Evangelica.1 -9.177e-01 2.429e-01 -3.779 0.000166 *** factor.AfroBrasileira.1 6.068e-01 4.303e-01 1.410 0.158794 factor.Turno.1 1.534e-03 1.034e-01 0.015 0.988169 factor.Aposentado.1 -4.516e-02 1.055e-01 -0.428 0.668597 factor.OcupaEstDiApenasDesemp.1 7.249e-02 1.411e-01 0.514 0.607474 factor.ComFamilia.1 -4.323e-01 2.128e-01 -2.031 0.042444 * factor.ComOutParentes.1 -5.029e-01 3.517e-01 -1.430 0.153011 factor.Republica.1 8.985e-03 1.959e-01 0.046 0.963429 factor.Sozinho.1 -2.475e-01 2.236e-01 -1.107 0.268673 factor.Pensao.1 -8.439e-01 4.000e-01 -2.110 0.035106 * factor.OutroMoradia.1 -5.262e-01 3.353e-01 -1.569 0.116880 factor.RU.1 -1.937e-01 1.059e-01 -1.830 0.067589 . factor.praec4.1 -1.583e-01 2.666e-01 -0.594 0.552951 IdadeA 3.787e-02 9.381e-03 4.037 5.79e-05 *** escola 8.576e-02 3.441e-02 2.492 0.012836 * RendaPC 4.045e-05 1.313e-05 3.080 0.002119 ** Dist 2.605e-05 1.296e-04 0.201 0.840689 PraecSoma 2.419e-02 3.086e-02 0.784 0.433427 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for quasipoisson family taken to be 0.6036898)
Null deviance: 834.67 on 1135 degrees of freedom Residual deviance: 706.16 on 1109 degrees of freedom AIC: NA
Number of Fisher Scoring iterations: 5
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI
Faculdade de Nutrição Universidade Federal de Alfenas
Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli
Alfenas, Minas Gerais, Brasil
*****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE
Eu apoio a ENEN "na luta por um Brasil sem fome"
"por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto)
E nunca votarei no PSDB/DEM!
_______________________________________________ R-br mailing list R-br@listas.c3sl.ufpr.br https://listas.inf.ufpr.br/cgi-bin/mailman/listinfo/r-br Leia o guia de postagem (http://www.leg.ufpr.br/r-br-guia) e forneça código mínimo reproduzível.
-- MARCOS BISSOLI Faculdade de Nutrição Universidade Federal de Alfenas Blog: bocademiamaldita.blogspot.com/ E-mail: mbissoli@gmail.com Twitter: #mbissoli Alfenas, Minas Gerais, Brasil *****Pense na Natureza antes de Imprimir***** Divulgue ON-LINE Eu apoio a ENEN "na luta por um Brasil sem fome" "por ĉiu popolo ties propran lingvon, por ĉiuj popoloj la esperantan" (para cada povo sua própria língua, para todos os povos o Esperanto) E nunca votarei no PSDB/DEM!
{kind=link}
participantes (4)
-
 Cesar Rabak
Cesar Rabak -
 Leonard Assis
Leonard Assis -
 Luiz Roberto Martins Pinto
Luiz Roberto Martins Pinto -
 Marcos Bissoli
Marcos Bissoli