
Olá Pessoal, boa noite! A seguir tem as explicações do problema e o código para reproduzir os resultados, procurei detalhar bem para facilitar a vida de quem se dispõe a ajudar. No trabalho disponível no link abaixo: http://www.lsie.unb.br/rbc/index.php/rbc/article/download/433/428 os autores validam o resultado de uma interpolação utilizando pontos de controle e calculando a Raiz Quadrada do Erro Médio Quadrático (REMQ) dado pela seguinte equação: [image: Imagem inline 2] Onde VMLTC é o Valor do Metro Linear de Testada Corrigida. Repeti o procedimento para 4 diferentes superfícies de interpolação e calculei o REMQ para cada uma como mostrado abaixo: #Download do arquivo no dropbox links <- c("https://www.dropbox.com/s/1grlssvxpihtcmt/valid.csv") tokens <- gsub("^.*/s/","",dirname(links)) fileNames <- basename(links) newLinks <- file.path("http://dl.dropbox.com/s", tokens, fileNames); newLinks for (a in newLinks) { tryCatch(download.file(a, dest=basename(a), mode='wb'), error=function(...) print("Falha no download!"))} valid<-read.table(file="valid.csv",sep=",",header=T,dec=".") # Função que calcula o REMQ (ve=valor estimado vr=valor real) remq<-function(ve,vr) { r<-ve-vr r2<-r^2 soma<-sum(r2) n<-length(r2) remq<-sqrt((1/(n-1))*soma) result<-c("Raiz do Erro Médio Quadrático"=remq) return(result) } # Calculando o REMQ remq.orig<-remq(valid[,2],valid[,1]) remq.mod.1.1<-remq(valid[,3],valid[,1]) remq.mod.2.1<-remq(valid[,4],valid[,1]) remq.mod.2.1.sar<-remq(valid[,5],valid[,1]) resumo.remq<-rbind(orig=remq.orig,mod.1.1=remq.mod.1.1,mod.2.1=remq.mod.2.1,mod.sar=remq.mod.2.1.sar);resumo.remq Agora gostaria de saber se as diferenças entre os REMQ são significativas estatisticamente e é aqui que está a minha dúvida, gostaria que avaliassem se o procedimento abaixo está correto, utilizo as diferenças entre os pontos de controle e os pontos obtidos nas superfícies para realizar a análise de variância e em seguida o Teste de Tukey. # Preparando para Teste de Médias m1<-valid[,2]-valid[,1] m2<-valid[,3]-valid[,1] m3<-valid[,4]-valid[,1] m4<-valid[,5]-valid[,1] dados.mod<-cbind(m1,m2,m3,m4);dados.mod dados.org <-data.frame(dif.mod=c(dados.mod[,1],dados.mod[,2],dados.mod[,3],dados.mod[,4]),Tipo=factor(c(rep("m1",20),rep("m2",20),rep("m3",20),rep("m4",20))),observ=factor(rep(1:20,4))) # Realizando a análise de variância tapply(dados.org$dif.mod,dados.org$Tipo,mean) ajuste<-aov(dados.org$dif.mod~dados.org$Tipo+dados.org$observ) summary(ajuste) posthoc<-TukeyHSD(x=ajuste,'dados.org$Tipo',conf.level=0.95);posthoc E então? Está correto utilizar as diferenças entre os pontos de controle e os pontos obtidos na superfície para realizar o teste de médias? Observe que os REMQ são bem diferentes, mas no teste médias as diferenças não são significativas, é aí que está a dúvida. Não sei se da forma como realizei o teste de médias está realmente avaliando as diferenças entre os REMQ. Desde já agradeço toda ajuda, *Hélder Gramacho * Recife-PE / *agrohelder@gmail.com <agrohelder@hotmail.com>*
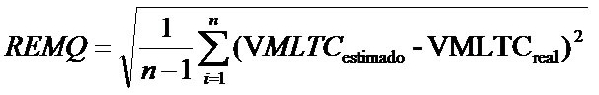{kind=link}